
Regardless of if we realise it or not, we apply our own biases to our cognitive thinking all the time. In the Information Technology (IT) world of diagnostics, one of the most influential is Anchoring Bias. Let’s start with the definition:
Anchoring or focalism is a cognitive bias where an individual depends too heavily on an initial piece of information offered to make subsequent judgments during decision making. Once the value of this anchor is set, all future negotiations, arguments, estimates, etc. are discussed in relation to the anchor.
Source: https://en.wikipedia.org/wiki/Anchoring_(cognitive_bias)
The important part to remember here is that subconsciously your brain can and will fixate on the first piece of information it finds. When it comes to fault finding, this can be the first error we see or the first reported information provided. This information (and therefore bias) can then cloud our judgement when it comes to further diagnostics of a fault, as we gravitate back to that singular piece of information instead of considering the bigger picture.
An IT person’s job is normally 90% fault finding, 10% doing. As the saying goes: “I’m not a geek, I’m just better at Googling than you”. What’s more, the saying is right. Nobody wants to spend 3 hours diagnosing the cause of a fault if they can simply jump straight to the fix.
Programmers are no different here too, the moment there’s a fault or error message it’s straight to Google to try and find someone else who’s had the same issue so that they can copy and paste the code to fix.

While finding the right result in Google can and does lead to a quick fix in many cases, it can also lead to a fallacy in your decision making process. In many cases, the focus is then on finding the right result for the error message, not why the error message existed in the first place.
A real world example
This is where Anchoring bias will rear its ugly head. If we see an error message about backups failing because it couldn’t run a certain command, we’re straight onto Google to find someone else who’s experienced that error message. IT faults can usually be broken down into three parts:

To start with, we normally only have the result and the output. For example:
| Result | Backups Failed |
| Output | Error message in the logs that the system didn’t have the correct permissions to create the backup file. |
In this scenario (which was a real world one), it’s very easy to race to the conclusion that the filesystem has the wrong permissions and start to google for “Vendor X error file permissions” or to even start instantly running commands to widen permissions.
Scenarios like this are what have led to so many S3 bucket leaks, where the wrong fix is applied to a backup failure fault and while it may fix the problem it’s created a far worse one behind the scenes.
Because the focus was all on what the error said, we lost sight of the actual fault itself. In this real world scenario, here was the resultant fault:
| Fault | Storage was full. |
The true fault ended up being that the backup system had run out of disk space. The particular vendor (seemingly) had no check in place to determine if it should try to create a new backup file and therefore failed during that particular area of the code.
But why the wrong error message? It’s normally because we see error messages where a try / catch or other similar error handling is too broad. For example, here’s some pseudo code for the above example:
try {
create_backup_file();
set_backup_permissions();
start_backup();
}
catch (err) {
panic("Failed to start the backup. Tried to set the backup permissions but couldn't do so");
}Because there’s multiple potential points of failure handled by a singular error message, it means the error itself may not be enough to effectively fault find.
Those who remember Windows 95 and had filled their hard drive may have been greeted with this error:
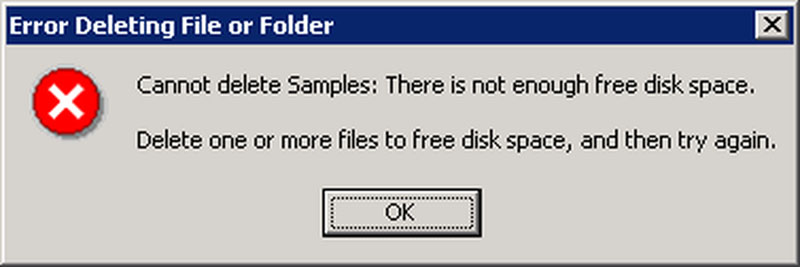
This one is obvious of course, but a simple example of how the wrong conclusion to a fault has led to a scenario which doesn’t make sense.
It gets worse
Even worse, when there’s no corresponding error message or log output for the fault at all, we can sometimes attribute the fault to one of the other (unrelated) error messages. This scenario still involves Anchoring bias as we’ve fixated on the first message seen and means we drift even further off track trying to find the fault. Time is now spent chasing errors which aren’t even related to the original fault, leading to the possibility of applying fixes which will make things worse instead of better. These “fixes” can then induce further faults, leading to a huge mess or catastrophic failure instead of a minor one.
Biases can also be combined subconsciously with other cognitive faults as well. As it was distinctly put by Erik Dietrich, you can also have Expert Beginners:
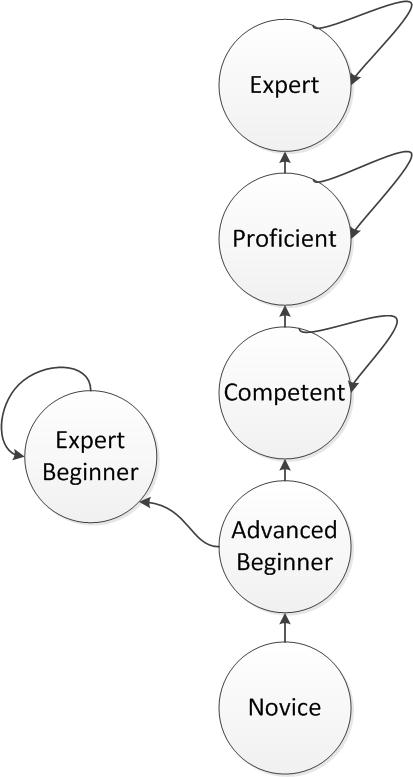
The difficulty is that as you learn, you can fall into the false trap that you understand a system well enough that your learning plateaus. This is normally due to only having a narrow view or understanding of a system, whereby you’ve only dealt with a small component of a large system and therefore reach the logical fallacy that you’ve learnt everything there is to know.
This narrowed view combined with anchoring bias leads will often strip you of the ability to consider wider views of the systems and the complexities involved.
How do we get around it?
There’s a few quick steps we can take:
Acknowledge the existence of bias: Like any bias, the first step is to acknowledge the existence. Once you know to be wary of this bias, it means you can compensate for it. There’s more than a dozen different biases which can affect your fault finding and decision making processes too, so it’s worth understanding how and where they may affect your thinking.
Write the fault out on paper: In the same way that Rubber duck debugging can help you because it forces you to put all the pieces together, writing it out on paper can also achieve the same thing. I also find drawing a timeline or flow diagram also helps, again because your brain will skip parts unless you force it to explicitly detail each stage.
Treat error messages with scepticism. Unless you can see the code itself to confirm, expect that they may not cover every fault scenario fully and may be generic messages. Think about the error message in context, does it fit the fault scenario? Did it occur timing wise when you’d expect it to trigger? Could it be triggered by a different scenario?
Look for the cause, not the symptom: This is the most effective method. Many of these examples can be traced back to the fault if you look for the cause. This isn’t to say we ignore the symptoms as such, but in a broad sense we use them as guidance not as gospel.
In our storage scenario, we can use the fact that it can’t set file permissions as a guide that the fault is to do with the filesystem and not as narrow as just file permissions themselves.
Running through rudimentary system checks in these scenarios (ie, looking at space, system load, network errors etc) can potentially serve as a quick sanity check and identify root causes early. At the very least, they will give you some confirmation that there’s not a high level or systemic fault.

